
在一個平凡的周末午後,高中老師安娜埋首於堆積如山的學生作文中。每一篇作文都承載著學生們的心血與努力,但三個班每人每週一篇長文寫作,安娜的批改速度總是趕不上學生提交的速度。安娜不禁感嘆:“如果有一個助手能幫我分擔一些工作該多好啊!”
某天,安娜老師偶然間在網上發現了一場比賽公告,這場比賽的目標正是開發一種自動評分系統來幫助教師們更有效地評估學生們的作文。這個系統不僅能夠減輕教師的工作負擔,還能確保學生獲得及時的反饋,這對於教育資源匱乏的地區來說尤為重要!因為在資源匱乏的地區,老師們更是身兼數職,難以提供足夠的個人化指導。如果能夠開發出一套開源的自動寫作評估(AWE)系統,那麽不僅能幫助老師減輕工作量,還能讓更多的學生受益。
今年四月,由 Vanderbilt University 在 Kaggle 上發起了一場為期三個月的競賽: Learning Agency Lab - Automated Essay Scoring 2.0,目標是鼓勵參賽者開發能夠自動化評分學生作文的模型,以節省教師的時間。
主辦方提供大約 24000 篇包括由 8 年級到 12 年級的英語學習者(ELLs)撰寫的議論文。每篇作文都根據 1 到 6 的評分標準進行評分,分數越高代表寫得越好。
下面是主辦方提供的訓練與測試資料簡介:
train.csv 前三筆 data 的截圖如下:
評分使用 quadratic weighted kappa,這是一種測量預測結果和 ground truth 之間一致性的指標。這一指標通常介於0(隨機一致)到1(完全一致)之間。如果實際的一致性低於隨機情況下預期的一致性,該指標可能會低於0。
目前為止,你已經了解比賽的目標、資料的數量、input 與 output 的格式了,以及評分的 metric 了。
❓❓可以暫停一下,思考看看,如果你是參賽者,你會如何設計你的解題方案呢❓❓
如果你上過一些 NLP 的課程(這邊大推李宏毅老師的機器學習課程,和陳縕儂老師的 ADL),可能會跟我當初一樣這樣想:
🤔 直接從 BERT 的兄弟姐妹--Roberta、DeBerta、Albert、Ambert--挑一個出來,再選合適的 pretrained model weight,直接訓練資料全下爆 train 一波,完事直接上傳,效果應該就不差了吧!
(這邊 code 也幫你準備好了,有興趣的話可以複製提交看看~請見 [1] )
然而代誌不是憨人想得那麼簡單,一頓操作猛如虎後...
抱歉...
我拉了坨大的💩💩....
Leaderboard 上只得到 0.77 分,排在兩千兩百名左右,Leaderboard 上要往下滑超久才能看到自己。
不過沒問題的,第一次嘗試提交,效果不好也沒關係~
可以把這次的方法當作 baseline,之後再慢慢改進。但問題是,這時候的你,只有 「LB(Leaderboard)上 0.77 分然後排名超後面」的反饋,線索少得可憐,真的有關於改進方法的頭緒嗎?
沒頭緒的時候,就讓我們去討論區圍觀大佬們的留言,挖掘看看有沒有什麼有用信息吧!
在開始前,我先簡單介紹兩個在kaggle討論區會時常看到的名詞:
CV分數指的是我們在訓練集上通過交叉驗證(Cross-Validation)得到的(QWK)分數。
LB分數是指我們在Leaderboard的公開榜上獲得的分數(Public Score)。由於這個分數僅基於實際測試數據的部分進行評估,因此我們不應該過度優化這個分數以追求在排行榜上的好位置。相反,我們應該努力使你的交叉驗證(CV)分數成為排行榜分數的良好指標,並盡量優化CV分數,縮小 CV 和 LB 分數的差距。
根據經驗,Kaggle 或是類似這樣的資料科學競賽,如果只是照搬模型過來直接無腦套用,通常不會有太好的名次。因為這麼容易想到的方法,通常別人也早就想到了。
大多時候,關鍵還是在每個賽題所獨有的「資料」上,如何去發覺資料背後隱藏的模式(pattern),往往是產生優勝方案的關鍵。
如果關注本次賽題的討論區,會發現有不少人在討論 "Data Leakage" 的問題。
在很多賽事都曾經出現 data leakage-數據洩露,有些是主辦方刻意為之,有些則是主辦方沒注意到的bug,總之就是讓參賽選手發現一些“意料之外”的information,但這個洩露出的資訊往往是因為在製造 dataset 的時候出現人為疏失,無法應用到真實業務場景。
例如在 2020 年華為曾經舉辦 昇騰杯-AI+行人重識別的競賽,參賽者要從給定的一堆圖片中,識別出是在拍同一個行人的圖片們。比賽數據的截圖如下(圖片來源[2]):
通過分析可以看出,雖然圖片的ID順序已經被重新打亂,但是它們的 time stamp 並未修改。如果根據時間戳來對圖片進行排序,就可以觀察到相同的行人常出現在時間接近的圖片里。利用這個特點,參賽者可以輕松地識別出包含同一行人的圖片。
這就是一種數據洩露,利用這個特徵就可以輕鬆獲勝。還有更多種資料科學競賽中常見的數據洩露形式,有興趣可以參考[2]這篇文章,上面關於華為的例子就來自這篇。
有時候在比賽後半階段,如果某些隊伍的成績顯著提升,超出了正常策略能達到的範圍,那麽他們可能發現了某種規律(當然,這也可能是由於他們技術更勝一籌、運氣更好、評分系統的問題、或是利用了多個帳號進行測試等)。所以如果你投入了大量努力卻依然與領先隊伍有較大差距,別氣餒,或許你可以試著尋找其中的規律。
接下來,讓我們回到本次賽題。
討論區的網友發現這題 training data 中的 essays 有不少是來自 "PERSUADE 2.0 corpus"。這是一件天大的喜事呀,因為該 dataset 中,有提到本次 training data 中所沒有揭露的 feature (prompt name),也許可以拿來利用。
甚至我們想的更大膽一點,如果 test data 也來自這個公開的資料集,那我們是不是直接拿 test data 中 essay 的文字去 match "PERSUADE 2.0 corpus" 的資料,就可以直接拿到它的 label 了。
如果真是這樣,我們現在原地宣布自己是本屆金牌得主,開始規劃一萬二美金怎麼花吧!
但是修但幾勒!!!
🤔 網友是怎麼發現這題可能存在的 Data Leakage 呢?
我怎麼就沒發現 training data 中有些 essay 的內容和 "PERSUADE 2.0 corpus" 的重疊呢?
❓❓一旦有懷疑的 public data resource 後,想想看如果是你,要怎麼確認主辦方提供的訓練資料,是否有使用到該個公開dataset的資料,以及有多少比例的 data 是完全一樣的呢?
如果有重疊的話,有多少是完全一樣的內容並且label是否也一樣?剩下沒有完全一樣的 data 中,會不會只有些微改寫內文而已,其實也可以視作一樣的 data ?要怎麼找出這種例子❓❓
下面提供一種做法:
🔎 Levenshtein distance(列文斯坦距離)是一種用來衡量兩個字符串之間差異的度量方式。
具體而言,它表示將一個字符串轉換成另一個字符串所需的最少編輯操作數。編輯操作包括以下三種:插入一個字符(Insertion, 刪除一個字符(Deletion),替換一個字符(Substitution)。在將levenshtein distance標準化時,會先計算出最少編輯操作術後,除上兩個字符串中的最多字符數。
🤔 這邊你也許會好奇,為什麼要先用 embedding similarity 找出 topk pair 再針對這些 pair 計算 Levenshtein distance 呢? 直接幫所有 pair 全部計算 Levenshtein distance 不就做好了?
使用 embedding similarity 的好處是計算速度很快,因此當 training data 和公開文本的數量很多時,可以先用 cosine similarity 找出 top results ,再繼續從這個被縮小的範圍找出 levenshtein distance 小於 0.3 的 pairs。因為向本題訓練資料有接近兩萬筆,pair 起來會有 n*n 筆資料,也就是接近 40 億個 pair,這樣計算量會超級大。但是如果 data size 很小的話,也可以直接計算 levenshtein distance 即可。
diff visualize 那些被 match 的 data。大致知道流程後,接下來我們實際寫 code 來 run 一遍上述六個步驟:
// train_df : 主辦方提供的 training data
// persuade_df: 網路上公開的 PERSUADE 2.0 corpus
train_df.text.str.strip().isin(persuade_df.full_text.str.strip()).sum()
// 確認是否那些 text exact match 的 data,他們的 label 也是一樣的
all_labels_match = train_df[train_df['text'].str.strip().isin(persuade_df['full_text'].str.strip())].merge(persuade_df, left_on=train_df['text'].str.strip(), right_on=persuade_df['full_text'].str.strip())['label_x'].eq(lambda x: x['label_y']).all()
🔎 Finding: 確認有 12873 / 17307 筆 text 和 label 都 exact match 的 data
def encode_texts(texts):
return model(**tokenizer(texts, return_tensors='pt', padding=True, truncation=True, max_length=max_length))
// 將 training data 和 persuade 2.0 的 data 轉成向量
train_embeddings = encode_texts(train_df['text']).last_hidden_state.mean(dim=1)
persuade_embeddings = encode_texts(persuade_df['full_text']).last_hidden_state.mean(dim=1)
// 計算兩者的 embedding similarity
similarity_scores = cosine_similarity(train_embeddings, persuade_embeddings)
// 找出 topk 高分的 persuade data indices
top_k_scores, top_k_indices = torch.topk(similarity_scores, k=k, dim=1)
match_data_pair = []
# 遍歷每個 train_df 文本和其對應的 top_k_indices
for i, indices in enumerate(top_k_indices):
match_found = False
for index in indices:
# 計算 normalized Levenshtein distance
train_text = train_df.iloc[i]['text']
persuade_text = persuade_df.iloc[index]['full_text']
distance = Levenshtein.distance(train_text, persuade_text)
normalized_distance = distance / max(len(train_text), len(persuade_text))
# 判斷距離是否小於 0.3,以及該 training data 對應的 persuade data 的 label 是否相同
# 若皆相同,則極有可能這兩筆 data 是 match 的
if normalized_distance < 0.3 and train_df.iloc[i]['label'] == persuade_df.iloc[index]['label']:
match_data_pair.append((i, index))
match_found = True
matched_persuade_indices = {index for _, index in match_data_pair}
matched_train_indices = {index for index, _ in match_data_pair}
#移除已經被 match 的 persuade data 與 train data 以縮小範圍、減少計算量
removed_persuade_df = persuade_df.drop(matched_persuade_indices)
removed_train_df = train_df.drop(matched_train_indices)
distances = []
#遍歷剩下沒有在前一步被 match 的 train 與 persuade data 的 normalized Levenshtein distance
for train_idx, train_text in removed_train_df['text'].iteritems():
for persuade_idx, persuade_text in removed_persuade_df['full_text'].iteritems():
distance = Levenshtein.distance(train_text, persuade_text)
distances.append({
'train_index': train_idx,
'persuade_index': persuade_idx,
'distance': distance
})
distance_df = pd.DataFrame(distances)
#找出 distance 小於 0.3 的 data pair
filtered_df = distance_df[distance_df['distance'] < 0.3]
#檢查如果 label 都相同的話就歸類到 match_data 裡面
for _, row in filtered_df.iterrows():
if train_df.iloc[row['train_index']]['label'] == persuade_df.iloc[row['persuade_index']]['label']:
pair = (row['train_index'], row['persuade_index'])
match_data_pair.append(pair)
🔎 Findings: 最終在 training data 找出 2 篇 essays 是相似的,但並沒有完全一樣;剩下 4432 筆 data 可能是完全新的未出現在現有的 persuade corpus 的 new data。
下圖統計剩下 4432 筆 training data 的每一個 essay 和與其餘 persuade data 的 lavenshtein score 最大值的分佈,可以發現距離都在 0.65 以上。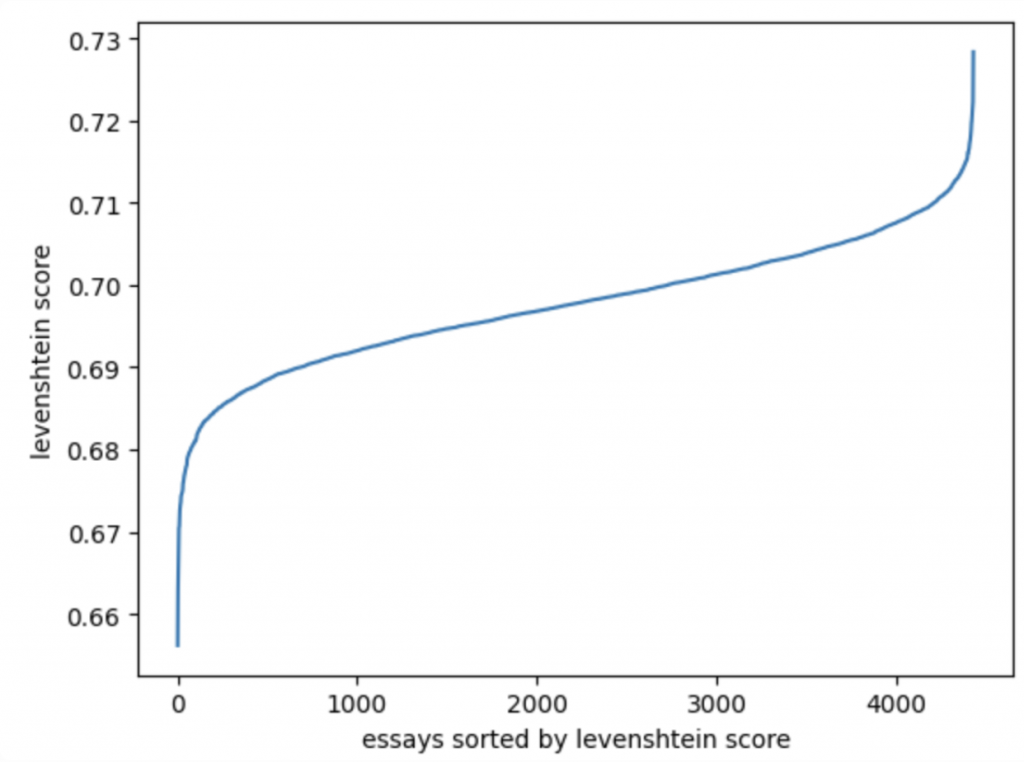
import difflib
import html
#Created using gpt4
def compare_texts(text1, text2):
# Create a Differ object
differ = difflib.Differ()
#Compare the texts character by character
diff = differ.compare(text1, text2)
#Process the differences to generate HTML
html_output = []
for char in diff:
if char.startswith("+"):
# Characters in text2 but not in text1, highlighted in blue
html_output.append(
f'<mark style="background-color: #AFEEEE;">{html.escape(char[2:])}</mark>'
)
elif char.startswith("-"):
# Characters in text1 but not in text2, highlighted in red
html_output.append(
f'<mark style="background-color: #DDA0DD;">{html.escape(char[2:])}</mark>'
)
else:
# Characters that are the same in both texts
html_output.append(html.escape(char[2:]))
html_content = "".join(html_output)
#Join the processed characters to form the complete HTML
return f"<pre style='font-size: 14px !important;'>{html_content}</pre>"
🔎 Findings:
下面用 compare_texts() 這個 function 來視覺化其中一組 match data pair 的差異:
亮藍色: PERSUADE text 有的文字,但是 training text 沒有
亮粉色: training text 有的文字,但是 PERSUADE text
沒有 highlight 就是兩邊都共有的文字

(擷取自[3]的圖片)
可以發現 training text 其實就是移除掉一些原文的 PII(Personal Identity Information)。
既然已經知道這次 kaggle 比賽 (AES 2.0) 提供的 training data 大部分都出自 PERSUADE 2.0,接下來很自然就會想問:
🤔 那實際上 testing dataset 會不會也有很大一部分來自 PERSUADE 2.0 Corpus 呢? 甚至會不會完全出自 PERSUADE 2.0 CCorpus 呢?
如果是的話,那最後繳交答案只要用 retrieve(檢索) 的方式就直接原地飛升獎牌榜了。也就是說,去 mapping testing data 的 essay 內容和 PERSUADE 2.0 最相似的那筆 data,再直接把該筆 data 的 label(公開資訊) 貼上就正解了!!
但這邊困難的地方是,如前面介紹資料格式時所提到,這是一場 code competition ,testing data 的內容是不可見的,我們無法直接分析 test data 的 essay 內容然後直接和 PERSUADE 2.0 Corpus 裡的 data 做 mapping,做和 training data 一樣的操作。
我們只能上傳一段代碼,在代碼中自動讀取系統後台存放的神秘的 test.csv 檔案,並把預測結果輸出到一個叫做"submission.csv"的檔案,讓系統後台自動跑腳本計算 submission.csv 的預測結果和 ground truth 的差距,最後系統會顯示 LB 的分數。
❓❓那在不可見 testing data 的內容的情況下,你要做什麼樣的假設、又要根據這個假設,利用平台的自動評分系統做什麼樣的實驗來驗證呢❓❓
有三種可能:
1. 測試資料完全來自 PERSUADE 2.0 Corpus
2. 測試資料部分來自 PERSUADE 2.0 Corpus
3. 測試資料完全不來自 PERSUADE 2.0 Corpus,和它一點關係都沒有
你的假設又會是什麼呢? 你會設計什麼樣的方式來驗證?
今天的關於賽題介紹、data leakage 的假設以及在訓練資料的初步驗證等內容,先在這邊告一個段落了。主辦方提供的測試資料到底是哪一種假設呢?歡迎明天回來,一起一探究竟。
謝謝讀到最後的你,希望你會覺得有趣!
如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵唷!
如果有任何回饋和建議,歡迎在留言區和我說✨✨
References:
[1]:https://www.kaggle.com/code/idv2005/deberta-baseline-train/notebook
[2]:https://www.secrss.com/articles/47835
[3]:https://www.kaggle.com/competitions/learning-agency-lab-automated-essay-scoring-2/discussion/493962#2760994
[4]:https://www.kaggle.com/code/nbroad/persuade-train-essays-analysis
(Kaggle - Learning Agency Lab - Automated Essay Scoring 2.0 解法分享系列)

 iThome鐵人賽
iThome鐵人賽